摘要:电商行业在中国已经走过很多年头,却依然没有停下迅猛发展的脚步,其中一些垂直领域的前景和市场仍然可观,例如化妆品电商。 原标题:聚美优品监控系统实践之路 原作者:2016/7/23 来源:中国网 作者:佚名
关键字:监控系统 聚美优品
电商行业在中国已经走过很多年头,却依然没有停下迅猛发展的脚步,其中一些垂直领域的前景和市场仍然可观,例如化妆品电商。作为女性的“必需品”,网购化妆品市场规模一直都在保持增长,作为国内较早成立并且首个赴美上市的垂直化妆品电商,聚美优品可能经历整个市场的不断进化,然而对这种变革感触最深的,恐怕要数聚美优品的运维工程师们。
60亿,只是开始
2013年时,聚美优品已经成立有3年之久,在这一年,他的全年销售额突破60亿元,这是个很高的数字,然而在聚美优品级运维工程师崔星眼里,这只是个开始。他回忆到,在2013年聚美优品的监控规模还小于200台,监控指标只有不到5000个,而这个数量在短短一年之内增加1000台、五万个指标,当大家都认为这个发展会放缓时,直到今日,聚美优品监控的指标已经超过了五十万个,架构也从最初的Nagios+Ganglia变为了如今的Zabbix+CMDB。
这样的改变是如何发生的?在早期,聚美优品遇到遇到过很多的问题:
1、监控系统自身水平扩展能力差:没有使用登录式,水平拓展也不是很好
2、不利于自动化:指标更新很复杂,配置一个指标,要更改指标项目,监控项目,这时候需要通过工具批量执行
3、告警策略的维护:变更代价太大
4、监控指标展示不太直观
5、数据采集也不统一…………
随着公司业务发展的变迁,为了解决问题,聚美优品意识到必须打造一个优秀的监控系统,而这个监控系统应具备的这样的条件:
强大的数据采集
高效的告警策略
个性化的告警设置
多维度的数据展示
可水平扩展
最终,聚美优品找到一种新思路,CMDB+Zabbix,满足优秀监控所具备的条件,最终成为自己开发的运维开发平台。
在路上,全新的监控平台
我们先来看一下聚美这套全新的监控平台的体系架构图:

图1 监控平台的体系架构图
从图中,我们可以看到有很多亮点:
数据采集:agent自动发现,主动推送模式
分布式监控:监控proxy可持续水平扩展
告警策略人性化:递延报警,报警暂停,按时段发送不同类型告警
DashbOArd:多维度数据展示,Top指标对比等功能
自动管理:自动清除下限机器,自动更新项目类型
数据采集
在数据采集方面,基础采集项全部采用自动发现,无需配置,实时从CMDB抓取项目、环境、状况等相关信息。拿到这些信息之后,再注册到Server上面去,Server有相关的一系列匹配。与此同时,采用主动模式上报监控数据,大幅度减轻监控Server端的压力。最后再禁用远程命令调用,保证安全高效。
_ueditor_page_break_tag_ 告警
针对告警聚美优品做了很多的优化和设置:
支持维护周期设置:想告警几天就设置告警几天,如果不想监控,可以永久关闭;如果某台机器凌晨五点不想告警的话,可以在这段时间进行关闭。
自定义告警类型:可以通过短信或者邮件告知。
告警列表:可以知道究竟有哪些告警现在没有消除,持续了多长时间,可以作为常规的考核可以是看持续性问题的观察。
告警分析:通过一些定义很严重的告警,分很多等级,不同的等级可以发送给运维人员。
告警递延:第一次告警是运维人员,如果运维人员半个小时之后没有处理,告警信息会上报给开发人员或者是部门主管。

图2 支持告警恢复通知
上面这张就是聚美优品的告警周期维护的截图,我们可以看出设置告警的时间,一些指标的查看,问题处理的时候,持续周期,警告时间,运维人员等一系列内容,都可以通过告警列表去知晓。
DashBoard
一个监控系统的好坏,很大程度上要看展示板的功能如何,聚美优品的展示板就是他们的特色之一:
项目指标聚合展示:将业务中一些比较重要的内容做展示,例如有20台机器的数据,聚合展示就可以把这20台机器做一些累加。可以把感兴趣放到总揽里面,聚合指标分为几类,例如CPU、内存,还有IR等。

图3 Dashboard
用户自定义Dashboard:开发人员和运维人员可以根据自己的习惯进行使用
项目层级展示:当项目很多时,可以归类已不同层级展示
指标对比分析:在遇到一些类似大促这样的情况时,假设有一百台机器,通过指标对比可以知道谁的网卡最高,例如图中我们看到蓝色波动,是不是这个时间段出现了一些异常,是配置错了?还是机器本身有问题,可以通过对比指标找出原因。

图4 Top指标实时统计
Top指标实时统计:实时展示某批机器下面的常规指标,可以看到当前最高指标的情况。通过把一些常规指标作为一个实时的展示在可以很清楚直观的知道这一些项目下面机器的情况,例如一些流量,IO的情况。
应用性能监控
聚美优品认为,一个平台的稳定除了需要对硬件监控之外,对于应用的监控同样重要。
使用听云App对聚美优品APP进行监控:
崩溃分析
通过听云App对崩溃进行分析,进行不断地bug修复,聚美优品每迭代一个新的版本崩溃率都会有明显的下降。
劫持分析

图5 劫持分析
对于绝大多数的电子商务网站来说,PC端业务有70%会转移到移动端,用户越来越关注PC和移动端的用户体验。随着直播的火爆,聚美优品最近逐步加大了在直播上的业务。但随之而来的可能就要去处理网络劫持现象的攀升。
1、通过使用听云App的劫持分析在全国范围内劫持比例在2个月下降50%。
2、聚美会派专人每天将听云统计的崩溃原始数据导入平台,再配合安排相关测试解决响应Bug,跟踪Bug处理进度,半年来崩溃比例下降明显,投诉率大幅下降,用户粘度提升显著。
3、听云App提供的行业数据对指导优化很有帮助,随着直播业务的展开,对标行业趋势很有必要。
APP流量分析
通过调查发现,一般有30%以上的用户会因图片体积过大而将APP进行卸载。聚美移动端在展示上存在较多的大图,对用户流量消耗比较大,通过听云App可对图片体积进行有效优化。行业参考值图片体积正常范围在50KB以内,优秀范围小于20KB,聚美iOS版本中的图片尝试了WEBP格式,大幅提升了油画效果。
第三方调用
某一时期某厂商HTTPDNS接口的错误率高于行业参考值,但是其整体错误率环比过去有明显下降。经过听云App第三方调用的分析,再经过研发优化,整体错误率大幅下降。
全国地区访问效果分析
经分析,在南方两个区域城市的用户体验不理想,且反映出虽其中一个区域运营商WiFi用户问题明显较多,但平均响应时间表现不很理想,随后便要进行优化。
WebView
有时候,部分HTML5页面中会存在JS脚本错误,如果Webview中吞吐率较高的HTML5页面存在脚本异常错误的话便可能会影响到业务,而这些也是通过听云App监测发现的。
使用听云Network对聚美优品进行监控:
压力测试
一般在大促上线前会使用听云Network进行压力测试,通过几十万注册用户,可控的终端,用脚本录制回放的方式对上线前业务进行现网业务模拟测试,可以模拟在大并发业务下的压力情况,看到大压力下全国用户的各省、市、运营商、接入方式的用户体验,及服务器的性能波动。
页面优化
一般的电商网站首页都会出现由于图片体积过大而造成的访问缓慢,有时候甚至图片体积超过了行业参考值,因此需要随时进行优化。听云Network的监测可以帮助及时发现问题,在调整后可以减少页面体积,提升用户体验,节省宝贵CDN带宽资源。
劫持分析,以下劫持发生的情况均来自于听云Network和听云App的劫持分析功能
从PC端上看,一般DNS劫持在整体劫持上占到3%左右,而整体劫持在北方发生的比例较高,内容劫持集中发生在南方。
从客户端看,DNS劫持较PC端较低,其中主要发生在北方区域,且集中在运营商4G服务商。
白屏测试
通过听云Network发现有时HTML5页面会出现白屏现象,其原因主要集中在HTTPS上,出现了较多的SSL握手时间较长,导致页面超时。
问题与思考,未来的监控平台之路
平台建设之路并非一帆风顺,在建设这套CMDB+Zabbix的监控平台过程中,聚美优品遇到了很多的问题,无论是展示板还是告警策略的设置,包括建设CMDB当中也遇到了一些困扰的问题,崔星表示,这些问题可能很有参考价值。
报警抖动
有些监控指标,例如磁盘空间,网络流量常常因为一些原因发生上下波动情况,从而收到大量的报警,为了防治这种不断波动的情况,可以通过设置Zabbix的TRIGGER来抑制这种情况发生。

图6 报警抖动
数据峰值平均化
Zabbix趋势数据存储了对应监控项目的历史数据在一个小时内的最大值,最小值,平均值,以及这一小时内采集数据的个数。如果要保留历史峰值,避免被平均化,那么在设置绘图时,就应该用max而不是avg。

图7 数据峰值平均化
数据库优化
在大型的Zabbix环境中,遇到的最大挑战是数据库。当采用最常见的MySQL时,每天采集的监控数大约是5亿条,如果不去管理这些数据,继续增长,那么数据库的性能会越来越差,相对的ZabbixServer的性能也会随之下架,这个怎么样解决?
第一是硬件设备,磁盘尽量采用SSD;随后对数据库参数调优,同时对Zabbix相关表进行表分区,关闭Zabbix自带的housekeepe。
最后MySQL表分区的操作:

图8 MySQL表分区
可以参考官方提供的分区方案:https://www.zabbix.org/wiki/Docs/howto/mysql_partition,把分区表建立好之后我们可以看到,大概可以承受聚美优品现在所实现的60多万个指标的压力。
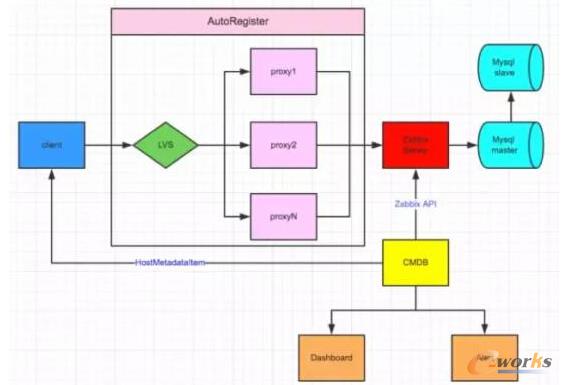
图9 60多万个指标的压力
60多万个指标的压力也并不是终点,随着业务的不断扩张,即使是现有运行良好的监控系统平台,也会有瓶颈的一天,技术也在不断的发展,未来的的监控系统建设之路又将是另一番天地。